Notes to write more on:
General topics: Hazards, pipelining, branch prediction, speculation, memory hierarchy, caches, virtual machines, I/O.
Table of Contents:
Memory Systems in Computers Link to heading
A crash course on memory systems in computers.
Modern computer systems rely on a hierarchy of memory components to efficiently manage data storage and retrieval. Understanding the organization, behavior, and optimization strategies of this memory hierarchy is essential for designing high-performance systems.
Memory Hierarchy and Latency Link to heading
The memory system in a computer typically consists of multiple levels:
- Registers
- Cache (L1, L2, L3)
- Main Memory (DRAM)
- Disk Storage (HDD/SSD)
The relative access latency of these components, when compared to a register, is approximately:
- Register: 1x
- Cache: 5x
- Main Memory: 300x
- Disk Storage: 5,000,000x
This vast difference highlights the importance of minimizing access to slower memory components.
CPU Execution Time and Memory Stalls Link to heading
CPU performance is affected by memory latency and can be modeled as:
$\text{CPU Execution Time} = (\text{CPU Clock Cycles} + \text{Memory Stall Cycles}) \times \text{Clock Cycle Time}$
Memory stall cycles can be expressed as:
$\text{Memory Stall Cycles} = \text{Number of Misses} \times \text{Miss Penalty}$
$\text{Memory Stall Cycles} = \text{IC}(=Instruction Count) \times (\text{Misses} / \text{Instructions}) \times \text{Miss Penalty}$
$\text{Memory Stall Cycles} = \text{IC} \times (\text{Memory Accesses} / \text{Instructions}) \times \text{Miss Rate} \times \text{Miss Penalty}$
For speculative execution, only committed instructions are counted.
Cache Design and Performance Metrics Link to heading
Cache Organization Link to heading
- A
tagin each cache block identifies the memory block address. - All tags are checked in parallel to maintain performance.
- A
valid bitindicates whether the cache block holds a valid address.
Cache Address Breakdown:
$\text{Cache Address} = \text{Block Address} + \text{Block Offset} = \text{Tag} + \text{Index} + \text{Block Offset}$
$2^{\text{index}} = \text{Cache Size} / (\text{Block Size} \times \text{Set Associativity})$
→ Fully Associative Caches have no index field and allow any block in any location.
Cache Replacement Policies:
- Random
- FIFO (First-In, First-Out)
- LRU (Least Recently Used)
Write Policies:
- Write-Through: Writes occur to both cache and memory simultaneously.
- Write-Back: Writes occur only to the cache; memory is updated when the block is replaced.
→ A dirty bit tracks modified blocks in write-back caches.
→ Write Buffers help reduce stalls in write-through caches.
Write Miss Handling:
- Write Allocate: Loads block into cache and performs write (like read miss).
- No-Write Allocate: Writes directly to lower memory, skipping the cache.
Performance Metrics: $$ \text{CPU execution time} = (\text{CPU clock cycles} + \text{Memory stall cycles}) \times \text{Clock cycle time} $$
$$ \text{Memory stall cycles} = \text{Number of misses} \times \text{Miss penalty} $$
$$ \text{Memory stall cycles} = \text{IC} \times \frac{\text{Misses}}{\text{Instruction}} \times \text{Miss penalty} $$
$$ \frac{\text{Misses}}{\text{Instruction}} = \text{Miss rate} \times \frac{\text{Memory accesses}}{\text{Instruction}} $$
$$ \text{Average memory access time} = \text{Hit time} + \text{Miss rate} \times \text{Miss penalty} $$
$$ \text{CPU execution time} = \text{IC} \times \left(\text{CPI}_{\text{execution}} + \frac{\text{Memory stall clock cycles}}{\text{Instruction}}\right) \times \text{Clock cycle time} $$
$$ \text{CPU execution time} = \text{IC} \times \left(\text{CPI}_{\text{execution}} + \frac{\text{Misses}}{\text{Instruction}} \times \text{Miss penalty}\right) \times \text{Clock cycle time} $$
$$ \text{CPU execution time} = \text{IC} \times \left(\text{CPI}_{\text{execution}} + \text{Miss rate} \times \frac{\text{Memory accesses}}{\text{Instruction}} \times \text{Miss penalty}\right) \times \text{Clock cycle time} $$
$$ \frac{\text{Memory stall cycles}}{\text{Instruction}} = \frac{\text{Misses}}{\text{Instruction}} \times (\text{Total miss latency} - \text{Overlapped miss latency}) $$
$$ \text{Average memory access time} = \text{Hit time L1} + \text{Miss rate L1} \times \left(\text{Hit time L2} + \text{Miss rate L2} \times \text{Miss penalty L2}\right) $$
$$ \frac{\text{Memory stall cycles}}{\text{Instruction}} = \frac{\text{Misses L1}}{\text{Instruction}} \times \text{Hit time L2} + \frac{\text{Misses L2}}{\text{Instruction}} \times \text{Miss penalty L2} $$
Also, $$ 2^{\text{index}} = \frac{\text{Cache size}}{\text{Block size} \times \text{Set associativity}} $$
Cache Miss Types:
- Compulsory Misses: First-time block access.
- Capacity Misses: Cache too small for data set.
- Conflict Misses: Due to limited cache lines in set-associative or direct-mapped caches.
→ Fully associative caches reduce conflict misses but are costly and can slow down clock rate.
Cache Optimizations Link to heading
- Larger Block Size
- Exploits spatial locality.
- May reduce miss rate.
- Can increase miss penalty and reduce total cache blocks, causing conflict or capacity misses.
- Common block sizes: 32B or 64B.
- Larger Cache Size
- Reduces miss rate.
- May increase hit time, cost, and power consumption.
- Higher Associativity
- Reduces conflict misses.
- Rule of thumb: A direct-mapped cache of size N has about the same miss rate as a 2-way set-associative cache of size N/2.
- Higher associativity can increase hit time.
- Multilevel Caches
- L1 cache speed affects CPU clock rate.
- L2 cache speed affects L1 miss penalty.
- L2 is typically inclusive of L1.
- L2 cache design focuses more on reducing miss rate due to fewer hits compared to L1.
- Priority to Reads Over Writes
- Essential in write-through caches.
- Write buffers are used to avoid read stall.
- On a read miss, systems check the write buffer and proceed if no conflicts are found.
- Avoiding Address Translation
- Virtually addressed caches bypass TLB lookup for hits.
Challenges include:
- Protection enforcement from TLB.
- Process switch requiring cache flush.
- Aliasing (multiple virtual addresses for same physical address).
Virtual Memory and the TLB Link to heading
- Virtual memory enables isolation and protection by mapping physical memory blocks to processes.
- Paging introduces latency, but modern systems use a Translation Lookaside Buffer (TLB) to cache address translations.
A TLB entry includes:
- Virtual address tag
- Physical frame number
- Valid, dirty, and protection bits
Virtual memory was not invented for sharing but to ease programming when memory was limited.
DRAM & Memory Controller Behavior Link to heading
Deep dive into DRAM timing, access behavior, and controller scheduling — essential for SoC performance architects optimizing latency, throughput, and power.
DRAM Architecture Basics Link to heading
Modern DRAM (e.g., DDR4, LPDDR5, HBM) is structured hierarchically:
- Channel: Independent data path to DRAM module.
- Rank: Group of DRAM chips sharing control/address lines.
- Bank Group → Bank: Sub-arrays inside each rank (e.g., 8 or 16 banks).
- Row → Column: Each bank has many rows, each row has many columns.
An overview of channel, rank, bank, row, and column organization:
 Reference:
Reference:Another view of channel, rank, bank, row, and column organization:
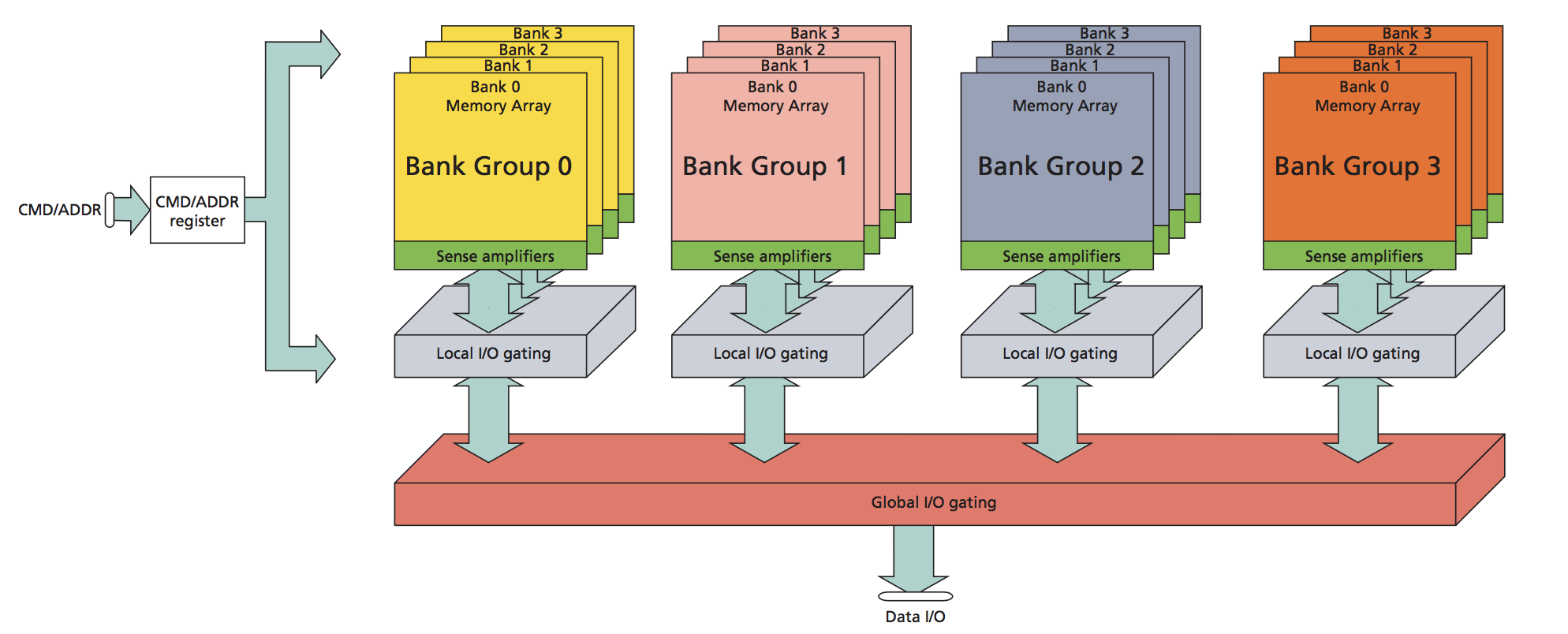 Reference: https://www.systemverilog.io/design/ddr4-basics/
Reference: https://www.systemverilog.io/design/ddr4-basics/
Accessing DRAM involves:
- Activating a row (load it into the row buffer)
- Reading/Writing columns
- Precharging the row (closing it)
DRAM Timing Parameters Link to heading
🔹 tCAS (Column Access Strobe Latency)
- Time between issuing a READ command and when data is available.
- Measured in clock cycles.
- Lower tCAS = faster read latency once row is active.
🔹 tRCD (Row to Column Delay)
- Time between row activation and issuing the READ/WRITE.
- Required for wordline to stabilize and bitlines to be ready.
🔹 tRP (Row Precharge Time)
- Time to deactivate (precharge) a currently active row before a new row in the same bank can be activated.
🔹 tRAS (Row Active Time)
- Minimum time a row must remain open after activation before precharging.
- Ensures data has been restored after access.
References:
- DDR basics: https://www.systemverilog.io/design/ddr4-basics/
- What is DRAM? https://chippress.online/2024/04/12/what-is-dram-hierarchy/
- DRAM Tutorial https://user.eng.umd.edu/~blj/talks/DRAM-Tutorial-isca2002.pdf
- Lecture: Main Memory https://course.ece.cmu.edu/~ece740/f10/lib/exe/fetch.php?media=740-fall10-lecture19-mainmemory.pdf
Q & A Link to heading
Q: What causes a bank conflict in DRAM and how can it be mitigated in SoC systems?
Cause: A bank conflict occurs when two or more memory accesses target different rows within the same DRAM bank at nearly the same time. Since a DRAM bank can have only one active row at a time, switching from one row to another requires:
- Precharging the current row (tRP)
- Activating the new row (tRCD)
- Then performing the read/write (tCAS)
This causes serialization of the requests → increased latency.
Mitigation Strategies in SoC Design:
🔹 Bank Interleaving
- Distribute consecutive memory addresses across different banks.
- Helps maximize bank-level parallelism (BLP).
🔹 Intelligent Memory Mapping
- Use memory controllers that map memory regions in a way that evenly distributes accesses across banks.
🔹 Request Reordering in the Controller
- Controllers (e.g., FR-FCFS) can delay non-urgent accesses that would cause conflicts and prioritize requests to already open rows.
🔹 Memory Subsystem Partitioning
Allocate dedicated DRAM banks per IP/accelerator to prevent interference (important in real-time or AI SoCs).
🔹 Increase Number of Banks
More banks = more chances to parallelize and reduce conflicts.
Q: Explain how FR-FCFS reduces average memory latency compared to FCFS
FCFS (First Come First Serve):
- Issues requests in the order they arrive.
- Ignores DRAM state (row hits/misses).
- Can result in frequent row buffer misses, causing tRP + tRCD delays.
FR-FCFS (First Ready, First Come First Serve):
- Prioritizes:
- Ready requests (row buffer hits)
- Among ready requests, chooses the oldest one
Why FR-FCFS is Better:
- Maximizes row buffer hit rate, avoiding the cost of activating/precharging rows repeatedly.
- Reorders non-conflicting requests to exploit open rows, while still maintaining fairness via FCFS among ready requests.
Example:
Requests arrive:
- Req1: Bank 0, Row A (currently open)
- Req2: Bank 0, Row B (needs row switch)
- Req3: Bank 1, Row X (idle bank)
FCFS would do: Req1 → Req2 → Req3
FR-FCFS would do: Req1 → Req3 → Req2
Better latency overall.
Q: Describe the DRAM access sequence and its timing parameters.
A complete DRAM access (READ) involves several steps, depending on whether it’s a row hit or miss:
🔸 Row Hit (same row already active)
- Command: READ
- Wait: tCAS → Data is available
🔸 Row Miss (different row is active or no row is active)
Command: PRECHARGE (if another row is open)
Wait: tRP
Command: ACTIVATE (new row)
Wait: tRCD
Command: READ
Wait: tCAS
Total delay = tRP + tRCD + tCAS (if switching rows)
⏱️ Timing Parameters Summary:
| Param | Meaning |
|---|---|
| tCAS | Delay from READ → data available |
| tRCD | Delay from ACTIVATE → READ/WRITE |
| tRP | Delay from PRECHARGE → next ACTIVATE |
| tRAS | Min time row must remain active after ACTIVATE |
Q: How would you design a DRAM controller to favor real-time workloads vs. throughput workloads?
Real-Time Workload Focus:
- Guarantee bounded latency, possibly at the cost of overall bandwidth
Design Choices:
- Deterministic access scheduling (e.g., TDMA or priority queues)
- Use bank partitioning to isolate real-time tasks
- Avoid starvation by enforcing maximum wait thresholds
- Disable aggressive row hit optimizations that could delay real-time accesses
Throughput Workload Focus:
- Maximize bandwidth and row buffer hit rate
Design Choices:
- Use FR-FCFS or PAR-BS to reorder requests for performance
- Exploit row locality and burst accesses
- Allow request batching and merging
- Can tolerate longer tail latency (non-real-time)
Trade-Offs:
- Real-time systems need predictability, throughput systems prioritize average-case performance
- Hybrid SoCs might use QoS-aware controllers (e.g., memory controller per domain or with class-of-service queues)
Q: What happens when multiple accelerators access the same bank simultaneously?
This leads to a bank conflict and causes access contention.
Consequences:
- Only one row can be active per bank → requests are serialized
- Accelerators must wait → increased stall cycles
- Row switches are costly (tRP + tRCD)
- Causes QoS violations or latency spikes in time-sensitive IPs
Mitigation Techniques:
🔹 Bank Partitioning: Assign dedicated DRAM banks to each accelerator to eliminate conflicts.
🔹 Interleaving Data Layout: Distribute data across banks so each accelerator hits different banks.
🔹 Memory Controller Arbitration: Implement QoS-aware scheduling to prioritize latency-sensitive accelerators (e.g., ML inference engine).
🔹 Use Scratchpad or Local SRAM: Offload frequent access data from DRAM into near-memory or tightly-coupled memory blocks.
🔹 Traffic Shaping/Throttling: Limit DRAM request rate from aggressive accelerators to prevent starvation.
Q: What is Class-of-Service queues? (QoS-Aware Memory Scheduling)
✅ Concept:
Class-of-Service (CoS) queues are logical or physical queues in a memory controller, where each class or workload type gets a dedicated queue and specific scheduling policy or priority.
📌 Use-Case: In a heterogeneous SoC with a CPU, GPU, NPU, and a camera ISP — each might have different service guarantees.
| Workload | Requirement |
|---|---|
| Real-Time Camera ISP | Predictable latency |
| NPU (ML Inference) | Sustained throughput |
| CPU | Moderate latency, low jitter |
| Background DMA | Best-effort |
🔧 Implementation: Separate queues per class (e.g., RT, BestEffort, Throughput, CPU) The arbiter picks requests based on class priority + policy.
🔧 CoS policies:
- Fixed priority
- Bandwidth cap per class
- Fairness enforcement
💡 Result: This ensures isolation between traffic classes, allowing real-time IPs to meet deadlines, while high-throughput clients get sufficient bandwidth.
Q: What is PAR-BS (Parallelism-Aware Batch Scheduling)?
✅ Concept:
PAR-BS is an advanced memory scheduling algorithm designed for multi-core SoCs that want to:
- Exploit bank-level parallelism (BLP)
- Avoid starvation
- Maintain fairness
📌 Key Ideas:
- Batching: Requests are grouped into batches of similar age to avoid starvation.
- BLP-aware selection: Within a batch, prioritize cores/IPs that maximize parallelism (i.e., spread across multiple banks)
- Fair Arbitration: Tries to balance throughput and fairness (unlike FR-FCFS, which can starve slower cores)
🔁 Flow:
- Pick oldest batch.
- Among that batch, pick request that enables most parallel bank activity.
- Rotate batches periodically.
🔧 Usage:
PAR-BS is used in data-center SoCs or client/server CPUs where many cores/IPs compete for DRAM — helps avoid a dominant core hogging all banks.
Q: What is TDMA and Priority Queue Scheduling? How do they help deterministic access?
✅ TDMA (Time-Division Multiple Access): Think of it as round-robin with time slots. Each IP gets a fixed time window (slot) in a cycle. Only that IP can issue DRAM accesses in its slot. Prevents interference or bandwidth theft.
💡 Determinism: Since the timing of slots is predictable, latency and bandwidth per client is bounded — crucial for real-time systems (e.g., camera pipelines, radar pre-processing, etc.)
Example:
- Slot 0–10ns: Camera ISP
- Slot 10–20ns: CPU
- Slot 20–30ns: NPU
✅ Priority Queue Scheduling: Each incoming request is placed in a queue based on its priority level. Higher-priority queues are always served first. Simple and works well for latency-sensitive + background workloads
🔧 Example Policy:
Queue 0: Real-time (always wins) Queue 1: CPU Queue 2: Background DMA
🟡 Risk: Starvation of low-priority clients → mitigated via aging or bandwidth guards
💡 Ensuring Deterministic Access Scheduling: To guarantee predictable access latency, use:
| Mechanism | Ensures |
|---|---|
| TDMA | Fixed latency slots per client |
| Static priority queues | Low-jitter, low-latency service for high-priority IPs |
| Bandwidth Reservation | Guarantees minimum bandwidth |
| Bank partitioning | Avoids conflicts and cross-interference |
| Timing-aware request shaping | Insert delays to align with time windows |
Q: Design a memory controller for an SoC with a camera ISP and a GPU. How do you ensure ISP deadlines are met without starving GPU throughput?
✅ Problem: Camera ISP: Real-time workload → needs low-latency, bounded access for frame processing. GPU: Throughput workload → can tolerate variable latency but needs sustained bandwidth.
✅ Design Solution: 🧱 1. QoS-Aware Class-of-Service Scheduling Assign two classes:
- Class 0: ISP → high priority, low-latency queue
- Class 1: GPU → best-effort or bandwidth-managed queue
⏲️ 2. TDMA (Time Division Multiple Access) for Hard Real-Time Reserve dedicated slots for the ISP in the memory access schedule:
Example: 2 slots out of every 5 cycles.
📊 3. Bandwidth Caps for GPU Enforce a bandwidth ceiling for GPU using token buckets or counters to prevent memory starvation.
📚 4. Request Ageing for Fairness Within GPU requests, apply aging or round-robin to ensure fairness across different GPU kernels or threads.
💡 Result: ISP always hits its latency budget (e.g., 16ms/frame). GPU can fill in the slack time to maintain throughput. No starvation + QoS isolation.
Q: How would you isolate high-bandwidth ML inference traffic from impacting real-time audio processing?
✅ Problem: ML inference (e.g., NPU or GPU): High bursty memory bandwidth (activations, weights) Audio pipeline: Requires consistent, low-latency access for streaming audio frames
✅ Solution: 🧱 1. Memory Partitioning Physically isolate memory regions and DRAM banks:
- Audio uses Bank Group 0
- ML uses Bank Groups 1–3
🧭 2. QoS-Aware Scheduling + Priority Queues Assign:
- Audio → High Priority Queue
- ML Inference → Lower Priority with fairness aging
⏲️ 3. TDMA for Deterministic Access Reserve time slots every few microseconds for audio streaming
📉 4. Throttling ML Bursts Shape ML memory traffic (e.g., using back-pressure from controller) Smoothen bursts to prevent DRAM queue congestion
💡 Result: Audio avoids jitter and buffer underruns. ML runs slightly slower but doesn’t corrupt real-time paths. Predictable behavior even under load.